Bien, rentrons dans le vif du sujet. Tout d'abord lancez votre implémentation de Common Lisp :
$ lisp / clisp / cmucl / sbcl ...
ou sous emacs avec slime : M-x slime
Vous obtenez un prompt (commençant par le signe > ou *) : le programme attend que vous tapiez des commandes.
Si vous tapez le chiffre 2 :
> 2 2
L'interpréteur lit (read) le nombre 2, l'évalue (Eval) et affiche (Print) le résultat. 2 s'évalue à 2 donc l'interpréteur affiche 2. De la même façon si vous tapez la chaîne de caractères "toto" :
> "toto" "toto"
De manière générale, l'interpréteur Lisp lit une expression afin de l'évaluer et d'afficher le résultat. La particularité du lisp est qu'une expression est une liste délimitée par deux parenthèses. Par exemple (1 2 3) est une liste de trois nombres.
Une expression est une liste de la forme : (fonction argument1 argument2...)
Les arguments sont d'abord évalués de la gauche vers la droite (argument1, puis argument2 ...) et ensuite la fonction est appelée avec les arguments évalués.
Par exemple pour l'expression suivante :
> (+ 1 2 3) 6
on applique la fonction (+) aux arguments 1, 2 et 3 et on obtient le résultat 1+2+3=6.
Une expression un peu plus compliquée serait :
> (* 2 (+ 3 4) 5) 70
qui correspond à l'opération 2*(3+4)*5 = 70. Ici, l'expression (+ 3 4) est évaluée à 7 et ensuite on applique la fonction (*) à 2,7 et 5 : (* 2 7 5) => 70.
La notation avec préfixe (la fonction en premier) peut paraître déroutante mais elle évite les ambiguïtés avec les règles d'application des opérations (la multiplication et la division sont prioritaires sur l'addition et la soustraction).
D'autre part avec ces quelques règles on définit toute la syntaxe du Lisp !
Il peut arriver que l'on veuille éviter d'évaluer une expression. Pour cela, on peut utiliser la fonction qui renvoie l'expression passée en argument sans l'évaluer :
> (quote (+ 2 3 4)) (+ 2 3 4)
Cette fonction est tellement utilisée que l'on peut la remplacer par l'abréviation apostrophe (') :
> '(+ 2 3 4) (+ 2 3 4)
On a souvent besoin de placer des commentaires dans le code. En Lisp, ceux-ci commencent par un point-virgule (;) et tous les caractères qui le suivent sont ignorés :
> 2 ; ceci est un commentaire 2
Les types
Le langage Common Lisp comporte un grand nombre de types, certains communs à d'autres langages, d'autre moins courants.
Tout d'abord, les noms des variables ou des fonctions sont des symboles, ils sont manipulables comme tout autre type :
> 'un_symbole UN_SYMBOLE
Ensuite, nous avons déjà vu les listes qui s'écrivent avec une parenthèse ouvrante et une parenthèse fermante. L'apostrophe permettant de ne pas évaluer l'expression :
> '(une liste 1 2 3 4) (UNE LISTE 1 2 3 4)
Ici, UNE et LISTE sont deux symboles. Ils sont mis en majuscules parce que le Common Lisp n'est pas sensible à la casse des caractères.
Viennent ensuite les types numériques. Les entiers ne sont pas limités en taille (c'est ce que l'on appelle des bignums).
> 1001 1001
Un exemple classique est de calculer factoriel 1000 (soit 1*2*3* ... *999*1000 = 1000!). Le résultat est un nombre de plus de 35000 chiffres, mais le Common Lisp le gère très bien en affichant ces 35000 chiffres ! La seule limite au grand nombre est la taille de la mémoire de l'ordinateur.
Le Common Lisp possède aussi les nombres rationnels qui s'expriment sous la forme numérateur/dénominateur. Ils permettent de représenter des nombres sous leurs forme exacte sans les problèmes de troncature dus à la représentation des nombres flottants.
> (/ 7 3) 7/3
Les nombres flottants sont représentés comme dans les autres langages :
> 3.1415 3.1415
Vous pouvez passer d'un type à l'autre grâce au fonction et :
> (float 1/3) 0.33333334 > (float 1/3 1d0) ; flottants en double précision 0.3333333333333333d0 > (rationalize 2.5) 5/2
Comme les chaînes de caractère :
> "une chaîne de caractère" "une chaîne de caractère"
Un caractères :
> #\a #\a
Les nombres complexes de la forme a + i b sont représentés sous la forme #C(a b) :
> #C(10 20) ; = 10+20i #C(10 20)
Ensuite, les tableaux sont créés avec la fonction ou avec une abréviation de la forme : #(element1 element2 ... elementn)
Un tableau peut contenir n'importe quel type d'élément, si on ne le précise pas au moment de créer le tableau. Pour des raisons d'efficacité, il peut parfois être nécessaire d'indiquer au compilateur le type des éléments du tableau. Chaque élément peut être obtenu grâce à la fonction (Attention, l'indice commence à zéro) et être fixé grâce à la fonction . Voici un exemple de manipulation d'un tableau :
> (setf tab (make-array 10 :initial-element 1)) #(1 1 1 1 1 1 1 1 1 1) > (aref tab 2) 1 > (setf (aref tab 2) "plop") "plop" > tab #(1 1 "plop" 1 1 1 1 1 1 1)
Les structures en Common Lisp ressemblent aux structures d'autres langages (comme le C). Lorsqu'on définit une structure avec , les fonctions et sont créés pour chaque champ.
> (defstruct essai plop plip) ESSAI > (setf s (make-essai :plop 10)) #S(ESSAI :PLOP 10 :PLIP NIL) > (essai-plop s) 10 > (setf (essai-plip s) "klm") "klm" > s #S(ESSAI :PLOP 10 :PLIP "klm") > (essai-plip s) "klm"
Lorsque l'on a besoin de stocker des données sous la forme clé/valeur, on peut utiliser une table de hachage. Dans l'exemple suivant, est la table de hachage, est la clé et est la valeur associée à cette clé.
> (setf h (make-hash-table :test 'equal)) #S(HASH-TABLE EQUAL) > (gethash "plop" h) NIL ; NIL > (setf (gethash "plop" h) 100) 100 > (gethash "plop" h) 100 ; T
Comme vous pouvez le constater, la fonction renvoie deux valeurs : la première correspond à la valeur associée à la clé, la seconde vaut s'il y a une valeur associée à la clé ou dans le cas contraire.
l'affichage
En Common Lisp, l'affichage est une fonction importante puisque la plupart des fonctions permettent d'écrire vers l'écran mais aussi vers un fichier ou une socket. Par exemple pour afficher un nombre :
> (print 10) 10 10 > (format t "x=~A~%" 10) x=10
La fonction affiche et renvoie l'argument, donc ici, elle affiche 10 et renvoie 10.
La fonction est à rapprocher de la fonction en C. Le premier argument correspond au flux vers lequel envoyer l'affichage ( représentant la sortie standard). Le second argument est une chaîne de formatage qui peut être plus ou moins complexe. Les autres arguments servant à alimenter la chaîne de formatage. Par exemple, la directive indique qu'il faut afficher le contenu du premier argument et la directive permet d'indiquer qu'il faut ensuite aller à la ligne.
> (format t "~&les éléments de la liste sont : ~{~A-~A ~}"
'(plop 1 plip 2 toto titi))
les éléments de la liste sont : PLOP-1 PLIP-2 TOTO-TITI
La chaîne de cet exemple est un peu plus complexe. Tout d'abord, la directive indique qu'il faut se placer en début de ligne, si ce n'est pas déjà le cas alors on va à la ligne. Ensuite les directives et indiquent qu'il faut parcourir la liste donnée en argument. La directive signale qu'il faut lire les éléments de la liste deux par deux et les afficher en les séparant par un tiret.
Pour plus de détails sur la fonction , je vous laisse vous reporter aux spécifications [3].
les variables
Comme dans tout langage, il est parfois nécessaire de stocker une valeur dans un endroit précis. C'est ce qu'on appelle une variable. On distingue deux types de variable. Les variables globales qui sont accessibles depuis n'importe quel endroit du programme. Par convention elles sont entourées d'asterisques (*). La fonction permet ensuite de modifier leur valeur :
> (defvar *var* 10) ; variables globales > *var* 10 > (setf *var* 'toto) TOTO > *var* TOTO
Les variables locales, quant à elles, ne sont accessibles que de manière limitée. Ceci évite les conflits ou les changements par inadvertance des variables globales. La fonction permet de définir une telle variable :
> (let ((a 'plop) ; variables locales
(b 10))
(print b)
a)
10
PLOP
> a
Erreur: la variable 'a' n'est pas définie.
Dans cet exemple, les variables et ne sont accessibles que dans le champ de définition du . Une remarque, lorsque la définition de la variable dépend de la variable , vous devez utiliser la fonction qui affecte la valeur de puis la valeur de .
(let* ((a 10)
(b (+ a 20)))
(format t "~&a=~A b=~A" a b))
a=10 b=30
Le Common Lisp contient un ramasse miette (Garbage collector) qui libère automatiquement la mémoire allouée pour une variable lorsque celle-ci n'est plus utile. Par exemple, les variables et sont automatiquement libérées à la sortie du .
Définir une nouvelle fonction
Lorsque l'on programme, on a souvent besoin de définir des fonctions qui permettent de décomposer le problème à résoudre. La fonction est là pour ça :
> (defun ma-fonction (x)
(format t "x=~A~%" x)
'fin)
> (ma-fonction "toto")
x=toto
FIN
Dans cet exemple, on définit la fonction qui prend un argument . La valeur renvoyée par la fonction étant la valeur de la dernière expression de la fonction. Donc ici, le symbole .
Le Common Lisp est un langage faiblement typé, c'est-à-dire que l'on n'a pas besoin de définir le type des variables. Ceci permet une grande souplesse. Mais si cela est nécessaire, il est tout à fait possible de tester leur type (avec les fonctions ou par exemple) ou de spécifier un type pour optimiser la vitesse d'exécution d'une fonction (par exemple avec la fonction ).
Les fonctions anonymes () sont un type de fonction particulier et très utile. Elles ont pour particularité de ne pas avoir de nom.
> ((lambda (x)
(format t "~&X vaut ~A" x))
10)
X vaut 10
Une de leur utilisation est d'être passée en argument dans une fonction.
> (defun ma-fonction (x y fonc)
(funcall fonc x y))
MA-FONCTION
> (ma-fonction 1 2 (function +))
3
> (ma-fonction 1 2 (lambda (x y) (format t "~&X=~A Y=~A" x y)))
X=1 Y=2
La nouvelle définition de prend en argument et et une fonction . Elle appelle ensuite la fonction avec les arguments et . Dans le premier cas, la fonction est la fonction (+). Dans le deuxième cas, au lieu de nommer une fonction, on se sert d'une fonction anonyme qui prend deux arguments et affiche leurs valeurs.
Cette manière de programmer permet de définir des fonctions très génériques dont le comportement dépendra de la fonction passée en argument. Un exemple est la fonction de tri qui accepte une fonction comme deuxième argument et qui permet de classer les éléments d'une liste suivant l'ordre voulu. Seul le choix de l'ordre des éléments change, l'algorithme de tri étant le même dans tous les cas.
> (sort '(1 4 2 3) (function >))
(4 3 2 1)
> (sort '(1 4 2 3) #'<)
(1 2 3 4)
> (sort '((1 a) (4 b) (2 c) (3 d))
(lambda (x y)
(< (first x) (first y))))
((1 A) (2 C) (3 D) (4 B))
Le dernier cas est un exemple de tri plus complexe sur la première valeur () d'une liste de deux éléments. De plus, comme la fonction est assez souvent utilisée, on peut la remplacer par l'abréviation .
Les fonctions locales sont un autre type de fonctions intéressant. Elle permettent de définir une fonction à l'intérieur d'une autre fonction. Cette fonction locale n'étant connue qu'à l'intérieur de la fonction principale :
;; fonctions locales
> (defun ma-fonction-globale (x)
(labels ((ma-fonction-locale (x y)
(format t "Local: x=~A y=~A~%" x y)))
(format t "Global: x=~A~%" x)
(ma-fonction-locale "toto" 'plop)))
> (ma-fonction-globale 12)
Global: x=12
Local: x=toto y=PLOP
Conclusion, avec les et les tout est permis pour protéger les variables et les fonctions de l'extérieur. Ce qui serait équivalent à des modules dans d'autres langages mais sans avoir plusieurs fichiers.
En Common Lisp, la définition des fonctions est très souple avec l'utilisation de paramètres optionnels, variables ou spécifiques. Quelques exemples :
;; arguments optionnels
> (defun ma-fonction (x &optional (y -10) z)
(format t "x=~A y=~A z=~A~%" x y z))
> (ma-fonction 10)
x=10 y=-10 z=NIL
> (ma-fonction 10 "toto")
x=10 y=toto z=NIL
> (ma-fonction 'toto "klm" 20)
x=TOTO y=klm z=20
;; arguments variables
> (defun ma-fonction (x &rest rest)
(format t "x=~A rest=~A~%" x rest))
> (ma-fonction 10)
x=10 rest=NIL
> (ma-fonction 10 "toto")
x=10 rest=(toto)
> (ma-fonction 'toto "klm" 20 100.5)
x=TOTO rest=(klm 20 100.5)
;; arguments specifiques
> (defun ma-fonction (x &key (y -10) z)
(format t "x=~A y=~A z=~A~%" x y z))
> (ma-fonction 10)
x=10 y=-10 z=NIL
> (ma-fonction 10 :z "toto")
x=10 y=-10 z=toto
> (ma-fonction 10 :z 'toto :y 'plop)
x=10 y=PLOP z=TOTO
Nous avons vu que la fonction permet de définir des variables locales. En Common Lisp, nous pouvons définir des fonctions à l'intérieur du champ d'action de variables locales. C'est ce que l'on appelle des fermetures ou closure en anglais.
> (let ((a 0))
(defun compte ()
(format t "a=~A~%" (incf a)))
(defun reset (&optional (new-a 0))
(setf a new-a)
(format t "a=~A~%" a)))
> (compte)
a=1
> (compte)
a=2
> (compte)
a=3
> (reset)
a=0
> (compte)
a=1
> (compte)
a=2
> (reset -1)
a=-1
> (compte)
a=0
> (compte)
a=1
> a
Erreur!
Dans cet exemple, la variable est partagée par les fonctions et , mais elle n'est pas accessible hors de la portée du (la dernière erreur quand on cherche à accéder à la variable hors du ). Ceci peut être mis en relation avec l'encapsulation en programmation orientée objet.
Documentation
Pour chaque fonction ou variable, nous pouvons définir une documentation qui permettra de savoir ce que fait la fonction ou à quoi sert la variable. Nous pourrons ensuite chercher parmi les fonctions ou variables et retrouver interactivement cette documentation.
> (defun ma-fonction (x)
"Affiche le carré de l'argument x"
(print (* x x)))
> (defvar *ma-var* 10 "Ma variable globale")
> (apropos 'ma-)
*MA-VAR* variable
MA-FONCTION fonction
> (documentation 'ma-fonction 'function)
"Affiche le carré de l'argument x"
> (documentation '*ma-var* 'variable)
"Ma variable globale"
> (describe 'ma-fonction)
MA-FONCTION est le symbole MA-FONCTION, est situé dans
#<PACKAGE COMMON-LISP-USER>
etc...
La dernière fonction, , décrit la fonction en donnant toutes les informations associées à cette fonction. Comme le nom du package où elle se trouve, sa définition, sa documentation...
Valeurs multiples
Nous avons vu précédemment que la fonctione renvoie la valeur associée à une clé et vrai () ou faux () si une valeur est associée à la clé ou non. Ceci est réalisé grâce à la fonction , la fonction permettant de retrouver ces valeurs.
> (values 1 2 'toto)
1
2
TOTO
> (defun ma-fonction (x)
(values 1 x 'toto))
> (multiple-value-bind
(ret1 ret2 ret3)
(ma-fonction 100)
(format t "~&ret1=~A ret2=~A ret3=~A" ret1 ret2 ret3))
ret1=1 ret2=100 ret3=TOTO
Ces valeurs multiples permettent de programmer de manière fonctionnelle : c'est-à-dire qu'une fonction prend des arguments en paramètre, mais ne les modifie pas. Par contre, elle renvoie un ou plusieurs résultats qui seront exploitables par les fonctions suivantes.
les conditions
Lorsque l'on veut influencer le comportement d'un programme, on a besoin de condition. Common Lisp fournit un grand nombre de tests plus ou moins spécifiques.
La condition la plus générale est le . Un test est vrai lorsqu'il renvoie ou une valeur différente de . Il est faux lorsqu'il renvoie ou une liste vide .
> (if (= 1 1)
'vrai
'faux)
VRAI
Attention, contrairement aux autres conditions, le n'exécutera qu'une seule expression. Si vous voulez exécuter plusieurs expressions, vous devez utiliser la fonction pour les grouper :
> (if t
(progn
(format t "~&Action 1")
(format t "~&Action 2"))
(format t "~&Le test est faux"))
Action 1
Action 2
La condition permet de définir plusieurs tests, comme une suite de imbriqués :
;;; (cond (test1 (action1) (action2)) ;;; (test2 (action3) (action4))) > (cond ((= 1 2) (princ "1 = 2") (format t "~&Test 1")) ((< 2 4) (princ "2 < 4") (format t "~&Test 2")) (t (princ "rien n'est vrai"))) 2 < 4 Test 2
Si tous les tests sont faux, le dernier sera exécuté puisque correspond à la valeur vrai. Cela correspond à la clause autre ou else/otherwise d'autre langage.
Les conditions et permettent d'écrire des tests plus spécifiques. On préfère écrire une condition avec plutôt qu'avec un sans condition contraire (ceci afin d'être clair sur ce que fait le programme). La condition est exécutée quand le test est vrai. La condition est exécutée quand le test est faux :
> (when (= 1 1)
(princ "1 = 1")
(princ " voila...")
(terpri))
1 = 1 voila...
> (unless (= 2 4)
(princ "2 n'est pas égale à quatre")
(terpri)
(princ "une autre expression"))
2 n'est pas égale à quatre
une autre expression
Lorsqu'on veut tester plusieurs cas à partir d'une seule expression, on peut utiliser la condition :
> (case (+ 2 3)
(4 (princ "résultat : 4"))
(5 (princ "résultat : 5"))
(6 (princ "résultat : 6"))
(t (princ "un autre résultat")))
résultat : 5
Comme nous l'avons déjà dit, le langage Common Lisp est très faiblement typé. Mais il est tout à fait possible de savoir quel est le type d'une variable ou du résultat retourné par une fonction. Supposons que nous définissions la fonction sans préciser le type des arguments et . Grâce à la fonction , nous pouvons savoir quel est le type de l'argument et ainsi prendre la bonne décision pour ajouter l'argument suivant.
> (defun somme (x y)
(typecase x
(number (+ x y))
(character (format nil "~C~C" x y))
(string (concatenate 'string x y))
(list (append x y))
(symbol (intern (format nil "~A-~A" x y)))
(t (list x y))))
> (somme 1 2)
3
> (somme #\a #\b)
"ab"
> (somme "plop" "plip")
"plopplip"
> (somme '(1 2 3) '(a b c))
(1 2 3 A B C)
> (somme 'toto 'plop)
TOTO-PLOP
> (somme #(1 2) #(3 4))
(#(1 2) #(3 4))
> (somme 1 'a)
Erreur: 'a n'est pas un nombre.
Une petite restriction concerne le fait que l'argument doit être du même type que l'argument . Si nous voulions traiter tous les cas, il suffirait d'écrire une fonction qui convertit le type de dans celui de . Ceci peut être réalisé grâce à la fonction .
Par exemple pour convertir un tableau en une liste :
> (coerce #(1 2 3) 'list) (1 2 3) > (somme '(1 2 3) (coerce #(a b c) 'list)) (1 2 3 A B C)
les itérations
Lorsque nous voulons exécuter plusieurs fois une opération, nous utilisons des itérations. Common Lisp fournit encore une fois un grand nombre d'itérations.
La récursivité est la première méthode historique et parfois très élégante. Elle consiste à appeler une fonction qui s'appelle ensuite elle même :
> (defun ma-boucle (n)
(format t "n=~A " n)
(if (<= n 0)
(format t "fin~%")
(ma-boucle (1- n))))
> (ma-boucle 10)
n=10 n=9 n=8 n=7 n=6 n=5 n=4 n=3 n=2 n=1 n=0 fin
Parfois, il est plus simple d'exprimer une boucle de manière impérative. La fonction permet de répéter plusieurs fois les mêmes opérations et la fonction permet de parcourir tous les éléments d'une liste :
> (dotimes (i 10 'fin)
(format t "i=~A " i))
i=0 i=1 i=2 i=3 i=4 i=5 i=6 i=7 i=8 i=9
FIN
> (dolist (l '(1 2 3 a b c d))
(format t "l=~A " l))
l=1 l=2 l=3 l=A l=B l=C l=D
La fonction permet de parcourir plusieurs listes en une seule fonction. Le premier argument de est une fonction que l'on veut appliquer à chacun des éléments de la liste. Elle prend autant d'arguments qu'il y a de listes à parcourir. Les autres arguments étant les listes à parcourir. Enfin, la fonction renvoie une liste contenant le résultat de la fonction en premier argument appliquée à chacun des éléments des listes (ici la somme des éléments de chaque liste).
> (mapcar #'(lambda (x y)
(format t "x=~A y=~A / " x y)
(+ x y))
'(1 2 3 4)
'(10 20 30 40))
x=1 y=10 / x=2 y=20 / x=3 y=30 / x=4 y=40 /
(11 22 33 44)
On peut utiliser la fonction dans le cas où l'on n'a besoin que des effets de bords sans la liste accumulée et renvoyée par .
Lorsque l'on a besoin d'une itération plus générale, on peut utiliser la fonction . Cette itération se décompose en trois parties.
1) L'assignation des variables de la forme
(variable valeur_initiale mise_à_jour)
exemple : (i 0 (1+ i))
la variable vaut d'abord
0 puis
(1+ i)
c'est-à-dire quelle est augmentée de 1 à chaque itération.
2) La condition de test, avec le résultat renvoyé par la boucle.
3) Le corps de la boucle.
Un exemple sera plus parlant :
> (do ((i 0 (1+ i))
(j 10 (1- j)))
((= i 10) 'fin)
(format t "i=~A j=~A " i j))
i=0 j=10 i=1 j=9 i=2 j=8 i=3 j=7 i=4 j=6 i=5 j=5 i=6 j=4
i=7 j=3 i=8 j=2 i=9 j=1
FIN
Ici, les variables sont et . La boucle s'arrête et renvoie le symbole quand le test (= i 10) est vrai, donc quand vaut 10. Le corps de la boucle étant la seule expression d'affichage.
Souvent les personnes ayant appris d'autres langages contenant moins de parenthèses sont effrayées par la boucle . Heureusement, grâce aux macros que nous verrons plus tard, le Common Lisp fournit la boucle ressemblant plus aux langages impératifs. Celle-ci est un vrai langage à l'intérieur du Lisp, elle est donc plus ou moins facile à maîtriser lorsque les directives se combinent.
> (loop for i from 3 to 10 for j = i then (* i i) do (format t "i=~A j=~A " i j)) i=3 j=3 i=4 j=16 i=5 j=25 i=6 j=36 i=7 j=49 i=8 j=64 i=9 j=81 i=10 j=100
Pour plus de détails, je vous laisse vous reporter aux spécifications qui restent le seul moyen d'espérer faire le tour de toutes les possibilités de la macro .
Bien, maintenant que nous avons plusieurs manières de faire des boucles, une question se pose : quel type de boucle choisir ? Une pratique en Lisp veut que l'on choisisse le type de boucle qui permet d'exprimer le mieux ce que fait le programme. On utilisera la récursion lorsqu'elle sera nécessaire ou les macros / si elles permettent de mieux cerner le problème. Par exemple, pour parcourir un arbre (une liste de listes imbriquées), le plus simple est d'utiliser la récursion, ce n'est pas la seule méthode, mais elle est assez «élégante». Une version avec une boucle impérative ne serait pas forcément plus claire.
> (defun parcourir-arbre (arbre)
(if (listp arbre)
(dolist (subarbre arbre)
(parcourir-arbre subarbre))
(format t "~A " arbre)))
> (parcourir-arbre '(1 2 ((a b ((c d) e) f) g 4) 5 6))
1 2 A B C D E F G 4 5 6
les fichiers
Quand on programme, on a souvent besoin de stocker des données. Les fichiers sont là pour ça. En Common Lisp, la macro qui permet de gérer les fichiers est . C'est une macro qui ouvre un flux et qui le ferme automatiquement lorsqu'on la quitte. De plus le corps de la fonction est protégé par un (que nous verrons plus tard) qui permet d'être sûr que le fichier est fermé même s'il survient une erreur.
Tout d'abord, on écrit quelques données dans le fichier :
> (with-open-file
(stream "toto.lisp" :direction :output
:if-exists :supersede)
(format stream "~S~2%~S~%" '(format t "~&coucou~%")
'(format t "2 + 2 = ~A~%" (+ 2 2))))
$ cat toto.lisp (FORMAT T "~&coucou~%") (FORMAT T "2 + 2 = ~A~%" (+ 2 2))
Puis on les lit :
> (with-open-file
(stream "toto.lisp" :direction :input)
(do ((ligne (read-line stream nil :eof)
(read-line stream nil :eof)))
((eq ligne :eof) 'fin)
(format t "Ligne: ~A~%" ligne)))
Ligne: (format t "~&coucou~%")
Ligne:
Ligne: (format t "2 + 2 = ~A~%" (+ 2 2))
FIN
Une petite remarque, les données que nous venons de sauvegarder sont des listes qui correspondent en fait à un programme Lisp. Nous pouvons donc charger ce programme et l'exécuter :
> (load "toto.lisp") ;; Chargement du fichier toto.lisp ... coucou 2 + 2 = 4
Ce petit exemple permet de visualiser une particularité du Lisp : Un programme en Lisp est une suite de listes. Donc un programme est une donnée comme une autre et peut être manipulé tel quel. Nous verrons par la suite qu'il est possible, grâce aux macros, d'écrire du code qui écrit du code. Ce qui fait dire à certains que le Lisp est un "langage de programmation programmable".
Compilation
Une question qui revient assez souvent est de savoir si le Lisp est un langage interprété ou compilé. De manière générale c'est un langage interactif compilé. Chaque fonction peut être compilée séparément grâce à la fonction . Un fichier complet pouvant être compilé avec la fonction .
> (defun ma-fonction (x y)
(+ x y))
> (compile 'ma-fonction)
Puis on peut voir le code produit par cette compilation grâce à la fonction :
> (disassemble 'ma-fonction)
Avec CLisp, le code est byte compilé et est lu par une machine virtuelle qui est portable sur n'importe quelle plateforme.
;;Déassemblage de la fonction MA-FONCTION ;;2 required arguments ;;0 optional arguments ;;Pas de paramètre &REST ;;Pas de mot-clé ;;4 byte-code instructions: ;;0 (LOAD&PUSH 2) ;;1 (LOAD&PUSH 2) ;;2 (CALLSR 2 53) ; + ;;5 (SKIP&RET 3) ;;NIL
A l'inverse, CMUCL produit du code machine qui est spécifique à un type de machine et un système d'exploitation.
;;* (disassemble 'ma-fonction) ;; ;;4802E448: .ENTRY MA-FONCTION(x y) ; (FUNCTION (T T) NUMBER) ;; 60: POP DWORD PTR [EBP-8] ;; 63: LEA ESP, [EBP-32] ;; ;; 66: CMP ECX, 8 ;; 69: JNE L0 ;; 6B: MOV [EBP-12], EDX ;; 6E: MOV [EBP-16], EDI ;; 71: MOV EDX, [EBP-12] ; No-arg-parsing entry point ;; 74: MOV EDI, [EBP-16] ;; 77: CALL #x100001C8 ; #x100001C8: GENERIC-+ ;; 7C: MOV ESP, EBX ;; 7E: MOV ECX, [EBP-8] ;; 81: MOV EAX, [EBP-4] ;; 84: ADD ECX, 2 ;; 87: MOV ESP, EBP ;; 89: MOV EBP, EAX ;; 8B: JMP ECX ;; 8D: NOP ;; 8E: NOP ;; 8F: NOP ;; 90: L0: BREAK 10 ; Error trap ;; 92: BYTE #x02 ;; 93: BYTE #x19 ; INVALID-ARGUMENT-COUNT-ERROR ;;94: BYTE #x4D ; ECX
Nous avons ici deux approches. Les deux fonctions sont compilées, mais dans un cas le code produit est un byte code qui devra être interprété par une machine virtuelle, dans l'autre cas, le code est du code machine.
Conclusion : le code produit par CLisp est extrêmement portable et le code produit par CMUCL est extrêmement rapide (on obtient des vitesses du même ordre qu'un programme écrit en C).
De plus, certaines implémentations produisent directement un executable, mais la plupart du temps, on compile et on charge les programmes directement à partir de leurs sources depuis la boucle d'évaluation ou depuis la ligne de commande du Lisp. Pour cela, soit on fait un script bash/batch, soit on se sert de packages qui permettent de gérer la compilation (et la recompilation), comme par exemple ASDF [11] qui est l'équivalent de make dans le monde du C. Une autre solution étant de faire une image de la mémoire en cours d'utilisation et de charger cette image depuis la REPL ou via la ligne de commande. Un programme en Lisp, comme nous l'avons déjà vu, n'étant qu'une suite d'instructions comme celles que l'on rentre dans la REPL. En général, l'extension des sources du programme étant en et la répartition des packages laissée à l'appréciation du programmeur.
Les exceptions : throw/catch et unwind-protect
Dans ce paragraphe, nous allons voir comment gérer les cas particuliers et les erreurs. Supposons que nous voulions commander une lame pour couper un objet. Nous spécifions la hauteur de la lame et la faisons descendre pour couper l'objet. Lorsque la hauteur de la lame devient trop basse (égale à zéro), la machine explose.
> (defparameter *hauteur* 5)
> (defun coupe ()
(format t "~A " (decf *hauteur*))
(when (zerop *hauteur*)
(format t "KABOOM ")))
> (defun mise-en-marche ()
(setf *hauteur* 5)
(format t "~&La lame descend: ")
(dotimes (i 7)
(coupe))
(format t "~&La lame est à la hauteur: ~A" *hauteur*))
> (mise-en-marche)
La lame descend: 4 3 2 1 0 KABOOM -1 -2
La lame est à la hauteur: -2
Dans cette première version, la machine dépasse la limite fixée, elle est donc détruite. Dans la version suivante, nous allons mettre en place un système d'arrêt d'urgence déclenché par un opérateur. Ceci est réalisé grâce aux opérateurs spéciaux et . Les expressions entourées par l'opérateur sont exécutées, mais dès que l'opérateur est appelé, le contrôle est rendu aux expressions suivant le . Et ceci depuis n'importe quel endroit du programme.
> (defun mise-en-marche ()
(setf *hauteur* 5)
(format t "~&La lame descend: ")
(catch 'stop
(dotimes (i 7)
(coupe)
(arret-urgence?)))
(format t "~&La lame est à la hauteur: ~A" *hauteur*))
> (defun arret-urgence? ()
(when (= *hauteur* 2)
(format t "~&Oula, stop!!")
(throw 'stop nil)))
La lame descend: 4 3 2
Oula, stop!!
La lame est à la hauteur: 2
Maintenant que l'arrêt d'urgence fonctionne, il ne reste plus qu'à faire en sorte de remettre la machine dans un état convenable avant de l'arrêter. C'est-à-dire qu'il faut remonter la lame et arrêter le moteur. Ceci peut être réalisé grâce à l'opérateur spécial . Celui-ci fonctionne de la manière suivante : les expressions sont exécutées dans l'ordre habituel, mais on a la garantie que quoi qu'il arrive dans la première expression, les expressions suivantes seront exécutées.
> (defun mise-en-marche ()
(setf *hauteur* 5)
(format t "~&La lame descend: ")
(catch 'stop
(unwind-protect
(dotimes (i 7)
(coupe)
(arret-urgence?))
(format t "~&Je remets la lame en place: ~A" (setq *hauteur* 5))
(format t "~&Et j'arrête le moteur.")))
(format t "~&La lame est à la hauteur: ~A" *hauteur*))
La lame descend: 4 3 2
Oula, stop!!
Je remets la lame en place: 5
Et j'arrête le moteur.
La lame est à la hauteur: 5
Ici, la lame est remise en place et le moteur arrêté alors que l'arrêt d'urgence a été déclenché et que le contrôle est transféré aux expressions suivant le .
En Common Lisp, certaines fonctions contiennent implicitement un , comme par exemple la macro qui garantit que le flux ouvert à l'entrée de la fonction sera fermé lorsque la macro se terminera même si une erreur survient. De plus, couplé à la macro , vous pouvez être sûr que votre programme ne se terminera pas de manière inopinée même s'il contient une erreur que vous pourriez corriger à "chaud".
la programmation OO : une fleur
Le Common Lisp contient en standard un système permettant la programmation orientée objets : CLOS (Common Lisp Object System). Dans l'exemple suivant, nous allons décrire et manipuler un objet Fleur. Celui-ci sera composé d'un objet Tige et d'un objet Tête. L'objet Fleur héritera des deux objets Tige et Tête pour former un seul objet. La seule méthode que nous définirons pour ces objets sera la fonction d'affichage.
Tout d'abord la Tige est constituée d'une couleur et d'une longueur :
> (defclass tige ()
((couleur :initarg :couleur-tige :initform "sans"
:accessor couleur-tige)
(longueur :initarg :longueur-tige :initform 10
:accessor longueur-tige)))
#<STANDARD-CLASS TIGE>
> (defparameter tige (make-instance 'tige :couleur-tige "bleue"))
TIGE
> (couleur-tige tige)
"bleue"
> (longueur-tige tige)
10
> (setf (longueur-tige tige) 20.5)
20.5
> (longueur-tige tige)
20.5
La fonction permet de définir une
classe, chaque champ pouvant contenir (entre autre) :
- Un argument permettant de fixer la valeur du champ à la création
d'une instance de la classe ().
- Un argument permettant de fixer la valeur par défaut du champ
().
- Un argument permettant d'accéder et de fixer la valeur du champ
().
La fonction permettant ensuite de créer une instance de la classe.
En Common Lisp, les méthodes permettant de manipuler les objets sont des fonctions génériques que l'on spécialise en fonction des objets à manipuler. Par exemple, on définit la méthode générique et on la spécialise, ensuite, pour la classe Tige. Ici, la méthode générique est définie de telle sorte que lorsqu'une classe hérite d'autres classes, les méthodes des classes héritées seront appelées les unes après les autres. Ceci est fixé grâce à l'option
> (defgeneric affiche (x)
(:method-combination progn))
#<GENERIC-FUNCTION AFFICHE>
> (defmethod affiche progn ((tg tige))
(format t "une tige:
couleur : ~A
longueur : ~A cm~%"
(couleur-tige tg)
(longueur-tige tg)))
#<STANDARD-METHOD AND (#<STANDARD-CLASS TIGE>)>
> (affiche tige)
une tige:
couleur : bleue
longueur : 20.5 cm
De la même manière, on définit l'objet Tête et la méthode pour la classe Tête.
> (defclass tête ()
((couleur-tête :initarg :couleur-tête :initform "sans"
:accessor couleur-tête)
(rayon-tête :initarg :rayon-tête :initform 2
:accessor rayon-tête)))
#<STANDARD-CLASS TÊTE>
> (defmethod affiche progn ((te tête))
(format t "une tête:
couleur : ~A
rayon : ~A cm~%"
(couleur-tête te)
(rayon-tête te)))
#<STANDARD-METHOD AND (#>STANDARD-CLASS TÊTE>)>
Enfin, nous définissons la classe Fleur qui hérite des deux classes Tige et Tête. Puis nous créons une instance de la classe Fleur.
> (defclass fleur (tige tête)
())
#<STANDARD-CLASS FLEUR>
> (defparameter fleur (make-instance 'fleur :couleur-tige "verte"
:couleur-tête "rouge"))
FLEUR
> (setf (rayon-tête fleur) 15)
15
> (affiche fleur)
une tige:
couleur : verte
longueur : 10 cm
une tête:
couleur : rouge
rayon : 15 cm
Comme vous pouvez le remarquer, nous n'avons pas défini de méthode pour la classe Fleur. En fait, elle hérite des deux méthodes des classes Tige et Tête et grâce à la manière dont elles sont combinées (), chaque méthode est appelée pour chaque partie de la Fleur (la Tige et la Tête). Bien évidement, on peut omettre le paramètre dans le cas où l'on voudrait simplement définir une méthode pour une classe sans se préoccuper de la manière avec laquelle elle sera combinée lors d'un héritage.
Pour ce paragraphe, je reste volontairement très succinct, puisque CLOS est un système très complet et un article pour lui tout seul ne serait peut être pas encore suffisant. Sachez tout de même que tous les mécanismes de la programmation orientée objet sont présents dans CLOS. L'encapsulation étant obtenue grâce aux packages que nous allons voir dans le paragraphe suivant.
Les packages
Quand un programme devient plus complet, il est parfois nécessaire de le découper en parties logiques. En Common Lisp, ceci est réalisé grâce aux packages. Mais contrairement à beaucoup d'autres langages, les packages en Common Lisp ne sont pas forcement découpés en fichiers ou répertoires : on peut avoir plusieurs packages dans un même fichier ou, à l'inverse, un package peut s'étendre sur plusieurs fichiers.
Dans l'exemple suivant, nous allons définir deux package : Plop et Toto. Chacun contenant une variable et une fonction . Seul la fonction sera accessible hors du package (ceci étant indiqué grâce au mot clé ).
> (defpackage :plop
(:export "FOO"))
#<PACKAGE PLOP>
> (defpackage :toto
(:export "FOO"))
#<PACKAGE TOTO>
> (in-package :plop)
PLOP> (defvar a 10)
PLOP> (defun foo ()
(format t "Plop: a=~A~%" a))
PLOP> (in-package :toto)
TOTO> (defvar a "klmpoi")
TOTO> (defun foo ()
(format t "Toto: a=~A~%" a))
TOTO> (in-package :user)
#<PACKAGE COMMON-LISP-USER>
> a
Erreur
> plop:a
Erreur
> toto:a
Erreur
> (plop:foo)
Plop: a=10
> (toto:foo)
Toto: a=klmpoi
L'accès à la variable n'est pas possible hors des packages, par contre les fonctions de chaque package sont accessibles à condition d'indiquer clairement quel package on souhaite utiliser. Dans le cas où les définitions des fonctions des packages n'entrent pas en conflit, nous pouvons utiliser la fonction pour indiquer que nous importons tous les symboles exportés d'un package.
> (use-package :plop) > (foo) Plop: a=10 > (toto:foo) Toto: a=klmpoi > (use-package :toto) 1 conflits de nom par USE-PACKAGE de (#<PACKAGE PLOP>) dans le paquetage #<PACKAGE COMMON-LISP-USER>.
les interfaces graphiques Lisp TK (ltk)
Lorsque l'on veut faire une interface graphique à un programme en Common Lisp, on peut utiliser la boite à outils TK grâce au package LTK de Peter Herth [12]. Il existe aussi des sorties vers OpenGL, SDL ou GTK.
> (load (compile-file "ltk"))
> (use-package :ltk)
> (with-ltk
(let ((b1 (make-button nil "Cliquez moi!"
(lambda ()
(format t "Cliqué!~&"))))
(b2 (make-instance 'button
:text "Quitter"
:command (lambda ()
(setf *exit-mainloop* t)))))
(pack b1)
(pack b2)))
Cliqué!
exit
NIL
Nous demandons d'abord de compiler, charger et utiliser le package LTK. Puis nous définissons deux boutons : l'un de manière fonctionnelle avec la fonction qui affichera le message "Cliqué!" lorsqu'il sera activé. Et l'autre en créant une instance de la classe button qui permettra de quitter l'interface graphique.
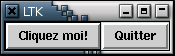
Voici une capture d'écran de la fenêtre obtenue :
Les macros : Étendre le langage pour qu'il s'adapte à ce que vous voulez.
Enfin, nous allons terminer cet article en abordant un des points qui rend le Common Lisp si évolutif et qui lui permet d'être encore là 50 ans après sa création : Les macros.
Une macro est un code qui doit produire un autre code lors de la compilation ou du chargement du programme.
Par exemple, en Lisp, la fonction renvoie le premier élément d'une liste. Le nom est historique mais pas toujours facile à retenir. On pourrait donc se demander comment utiliser un nom plus simple comme en français. Pour cela, nous pouvons définir la macro :
> (defmacro premier (x)
(list 'car x))
> (premier '(a b c d e))
A
Lors de la compilation, chaque fois que le compilateur rencontrera la fonction , il la remplacera par la list (list 'car x). Ce qui correspondra à 1 lors de l'exécution du programme.
Pour simplifier l'écriture d'une macro, nous allons avoir recours aux backquotes. Celles-ci permettent d'inverser le comportement des fonctions et :
> (defvar a 10) > (defvar b '(1 2 3)) > `(a vaut ,a) (A VAUT 10) > `(b vaut ,b) (B VAUT (1 2 3)) > `(les éléments de b sont ,@b) (LES ÉLÉMENTS DE B SONT 1 2 3)
Donc, la fonction correspond à la fonction : aucun élément de la liste n'est évalué par défaut. Si on veut évaluer un élément particulier, il suffit de le faire précéder d'une virgule (,). Dans ce cas, l'élément est remplacé par la valeur de son évaluation. La présence de la forme permet, quant à elle, d'insérer les éléments d'une liste directement dans la liste résultante.
Pour voir le code produit par la macro , nous utilisons la fonction :
> (macroexpand-1 '(premier '(1 2 3))) (CAR '(1 2 3))
Donc, à la compilation, tous les appels à la macro seront remplacés par des appels à la fonction .
Nous pouvons aussi définir la macro grâce aux backquotes :
> (defmacro premier (x)
`(car ,x))
> (premier '(1 2 3))
1
> (macroexpand-1 '(premier '(1 2 3)))
(CAR '(1 2 3))
T
Cette forme a l'avantage de ressembler très fortement au code généré par la macro.
Nous allons donc nous servir des macros pour définir notre propre langage. Supposons que nous voulions apprendre la programmation à un enfant. Grâce aux macros, nous pouvons développer un langage qui lui sera plus facile à aborder.
Tout d'abord, pour faire quelque chose dans ce langage, nous définissons des fonctions grâce à la fonction . Pour simplifier les choses, nous allons l'appeler et faire en sorte qu'elle ne prenne pas d'arguments et qu'elle rajoute les parenthèses autour du corps de la fonction. Nous définissons aussi la fonction :
> (defmacro pour (name &body body)
`(defun ,name () (,@body)))
> (defun écrire (&rest rest)
(dolist (i rest)
(princ i)
(princ " "))
(terpri))
Ensuite, nous avons besoin de faire des boucles, ce sera la fonction , et nous ferons en sorte qu'elle ait une syntaxe proche du français :
> (defmacro répéter (num fois &body body)
`(do ((nombre 1 (1+ nombre)))
((> nombre ,num))
,@body))
Dans les deux macros, l'argument correspond au corps de la fonction. Et grâce à la forme il est insérer tel quel dans le code produit par la macro.
Voila, maintenant, nous pouvons écrire dans ce nouveau langage simplifié :
> (pour avancer
écrire "J'avance")
> (pour tourner_à_90°
écrire "Je tourne à angle droit")
> (pour faire-un-carré
répéter 4 fois
(avancer)
(tourner_à_90°))
> (faire-un-carré)
J'avance
Je tourne à angle droit
J'avance
Je tourne à angle droit
J'avance
Je tourne à angle droit
J'avance
Je tourne à angle droit
Bien, revoyons l'action au ralenti. Tout d'abord, nous définissons les actions et . Voici quel sera le code produit par la macro dans ce cas :
> (macroexpand-1 '(pour avancer
écrire "J'avance"))
(DEFUN AVANCER ()
(ÉCRIRE "J'avance"))
Donc, lors de la compilation, le compilateur remplacera la fonction par la fonction en rajoutant les parenthèses nécessaires. La fonction sera définie comme si on avait utilisé le dès le départ.
La macro n'est pas assez évoluée pour avoir un corps de plus d'une expression mais elle est plus simple à écrire que le correspondant avec toutes ses parenthèses.
De la même manière, nous pouvons voir le code produit par l'action :
> (répéter 4 fois
(écrire "Nombre vaut" nombre))
Nombre vaut 1
Nombre vaut 2
Nombre vaut 3
Nombre vaut 4
> (macroexpand-1 '(répéter 4 fois
(écrire "Nombre vaut" nombre)))
(DO ((NOMBRE 1 (1+ NOMBRE)))
((> NOMBRE 4))
(ÉCRIRE "Nombre vaut" NOMBRE))
Dans ce cas, il y a plusieurs choses à remarquer. La première est que le paramètre ne sert à rien, il est juste là pour aider à la rédaction de la fonction et il est éliminé par le compilateur : il n'apparaît donc pas dans le code produit et ne pénalise pas les performances.
La deuxième chose est que la variable est utilisée comme variable dans la boucle. Quelqu'un qui n'est pas averti du fait que la variable est mise à jour à chaque itération pourrait être très gêné de voir cette variable augmenter alors qu'il n'a rien demandé. C'est ce que l'on appelle la capture de variables.
Enfin, un bug plus gênant peut intervenir à cause de cette macro si le paramètre de la macro contient des effets de bord. Essayez par exemple :
> (setf x 10)
> (répéter (decf x) fois
(écrire "Nombre vaut" nombre))
Nombre vaut 1
Nombre vaut 2
Nombre vaut 3
Nombre vaut 4
Nombre vaut 5
Si vaut 10, (decf x) vaut 9. On pourrait s'attendre à voir la boucle s'exécuter 9 fois. Or, elle ne s'exécute que 5 fois. La raison en est simplement qu'à chaque itération la variable est décrémentée dans le test de sortie de la boucle.
> (macroexpand-1 '(répéter (decf x) fois
(écrire "Nombre vaut" nombre)))
(DO ((NOMBRE 1 (1+ NOMBRE)))
((> NOMBRE (DECF X)))
(ÉCRIRE "Nombre vaut" NOMBRE))
Il existe des techniques simples qui permettent d'éviter ces bugs mais elles nous entraîneraient beaucoup trop loin pour cet article.
Dans tous les cas, les macros permettent d'adapter le Lisp au problème que l'on a à traiter plutôt que l'inverse. C'est le rôle de tout langage de programmation : on écrit en C plutôt qu'en assembleur. Le compilateur C se chargeant de produire le code assembleur. Il en est de même pour le Lisp ou tout autre langage de programmation dit de «haut niveau».
Conclusion
Voila, j'espère que ce petit tour dans la REPL du Lisp vous aura donné envie d'aller plus loin avec ce . Dans tous les cas, n'hésitez pas à poser vos questions sur l'Usenet comp.lang.lisp ou fr.comp.lang.lisp et sur le channel #lisp sur Freenode. Le Cliki [14] étant un bon point de départ pour approfondir cette petite visite.
Et le mot de la fin :
> (quit)
ANNEXES
Exemples d'utilisation :
[1] http://alu.cliki.net/Success%20Stories
[2] http://alu.cliki.net/Industry%20Application
Références :
[3] http://www.lispworks.com/documentation/HyperSpec/Front/index.htm
[4] http://www-2.cs.cmu.edu/Groups/AI/html/cltl/cltl2.html
Implémentassions libres :
[5] http://www.cliki.net/Common%20Lisp%20implementation
[6] http://clisp.cons.org/
[7] http://www.cons.org/cmucl/
Ressources :
[8] http://common-lisp.net/project/slime/
[9] http://www.lisp-p.org/15-vim/
[10] http://jabberwocky.sourceforge.net/
[11] http://www.cliki.net/asdf
[12] http://www.peter-herth.de/ltk/
Sites :
[13] http://www.lisp.org/
[14] http://www.cliki.net/
[15] http://common-lisp.net/